零基礎入門數據挖掘 系統學習路徑與實踐指南
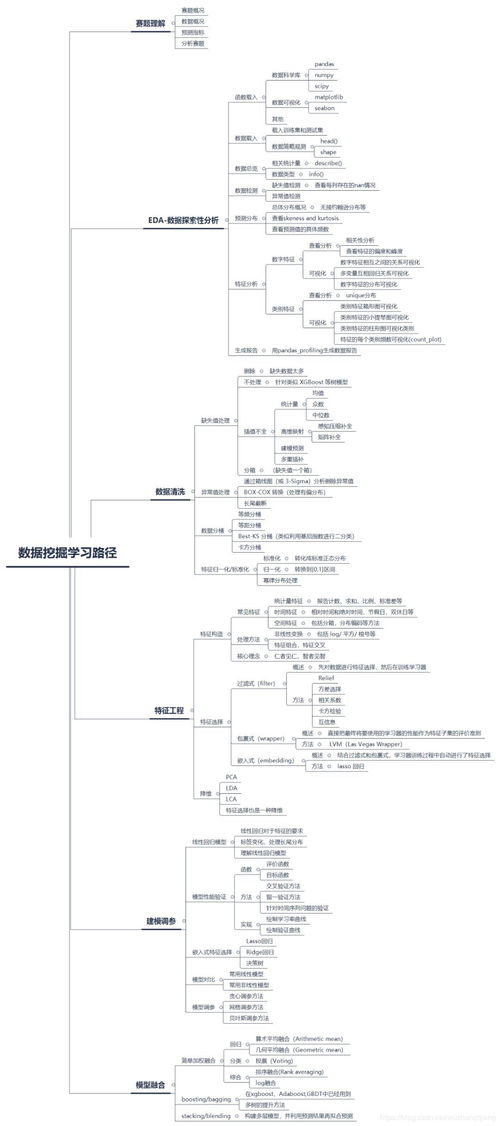
隨著大數據時代的到來,數據挖掘已成為各行各業的核心技能之一。對于零基礎的初學者來說,掌握數據挖掘不僅能夠打開職業發展的大門,更能培養以數據驅動決策的思維能力。本文將為你規劃一條清晰、系統的學習路徑,從基礎知識到實踐應用,逐步引領你走進數據挖掘的世界。
一、 建立堅實的數學與統計基礎
數據挖掘的底層邏輯建立在數學和統計學之上。初學者無需畏懼,可以從最核心的概念開始:
- 線性代數:理解向量、矩陣、特征值等概念,它們是機器學習算法的基石。
- 概率論與數理統計:掌握概率分布、假設檢驗、回歸分析等,這是理解數據不確定性、進行推斷和建模的關鍵。
- 微積分:了解導數和積分的基本思想,有助于理解優化算法(如梯度下降)的工作原理。
建議通過在線課程(如Coursera、可汗學院)或經典教材進行系統性學習,重在理解概念而非復雜的推導。
二、 掌握一門編程語言與數據處理技能
工欲善其事,必先利其器。Python是目前數據科學領域最主流的語言。
- 學習Python基礎:掌握語法、數據結構、函數和面向對象編程。
- 精通核心數據科學庫:
- NumPy:用于高效的數值計算。
- Pandas:用于數據清洗、處理和分析的利器。
- Matplotlib/Seaborn:用于數據可視化,將數據轉化為直觀的圖表。
此階段的目標是能夠熟練地導入、清洗、探索和初步可視化一個數據集。
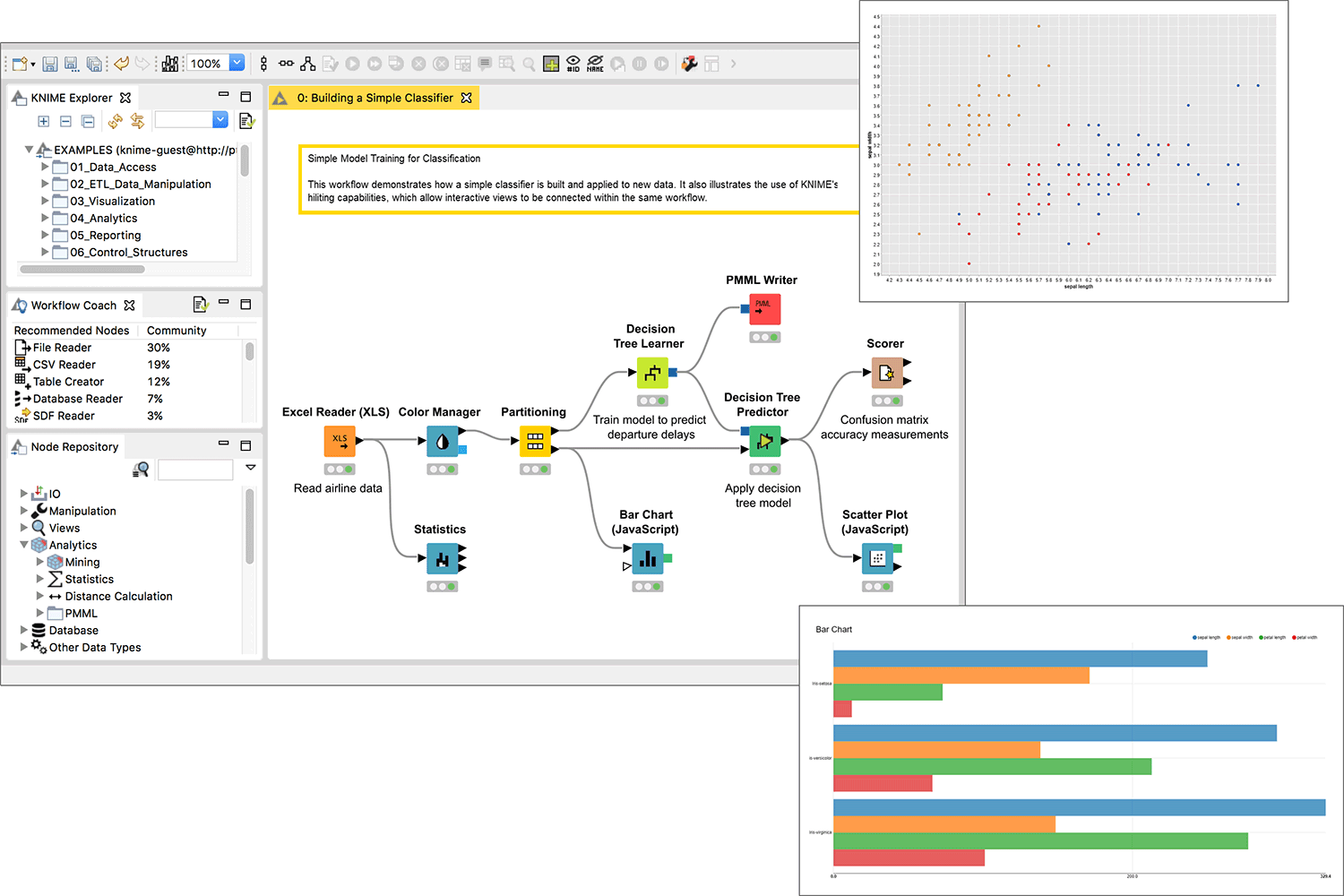
三、 學習機器學習核心算法
這是數據挖掘的核心內容。建議從理解原理和簡單應用開始:
- 監督學習:
- 回歸問題:線性回歸、決策樹回歸等,用于預測連續值。
- 分類問題:邏輯回歸、K近鄰、樸素貝葉斯、支持向量機、隨機森林等,用于預測類別標簽。
- 無監督學習:
- 聚類:K-Means、層次聚類,用于發現數據內在的分組。
- 降維:主成分分析(PCA),用于壓縮數據并可視化。
學習時,結合Scikit-learn庫進行實踐,重點關注算法的適用場景、輸入輸出及參數含義。
四、 深入數據挖掘專項技術與實踐
在掌握基礎后,可以深入更專業的領域:
- 特征工程:學習如何從原始數據中構建、選擇對模型最有價值的特征,這是提升模型性能的關鍵步驟。
- 模型評估與優化:掌握交叉驗證、網格搜索、評估指標(如準確率、精確率、召回率、AUC等)以及解決過擬合/欠擬合的方法。
- 專項挖掘任務:了解關聯規則挖掘(如Apriori算法)、文本挖掘(自然語言處理基礎)、時間序列分析等。
五、 通過項目實踐鞏固與提升
“紙上得來終覺淺,絕知此事要躬行。”實踐是學習數據挖掘的最佳途徑。
- 使用經典數據集:在Kaggle、天池等平臺找到入門級競賽(如泰坦尼克號生存預測、房價預測),復現優秀方案。
- 解決實際問題:嘗試挖掘與分析自己感興趣領域的數據,如分析電影評分數據、電商銷售數據或社交媒體數據。
- 構建完整流程:從業務理解、數據獲取、清洗、探索、建模、評估到結果呈現,獨立完成一個端到端的小項目。
六、 培養數據分析思維與業務理解
技術是手段,解決問題才是目的。優秀的挖掘者必須具備:
- 業務理解能力:將模糊的業務問題轉化為明確的數據分析問題。
- 批判性思維:對數據和模型結果保持質疑,思考其背后的含義與局限性。
- 講故事與可視化能力:能夠將復雜的技術結果,用清晰、有說服力的方式呈現給非技術人員。
學習資源推薦:
- 書籍:《Python數據科學手冊》、《機器學習》(周志華,西瓜書)、《統計學習方法》。
- 在線課程:吳恩達《機器學習》(Coursera)、DataCamp互動課程。
- 社區:Kaggle、GitHub、Stack Overflow、國內的技術博客和論壇。
零基礎入門數據挖掘是一場循序漸進的旅程。這條路徑從基礎理論出發,經過工具掌握、算法學習、專項深入,最終落腳于項目實踐與思維培養。保持好奇心與耐心,堅持學習與動手實踐,你將能逐步解鎖數據中的隱藏價值,成為一名合格的數據挖掘與分析實踐者。
如若轉載,請注明出處:http://m.lunwenshijie.cn/product/31.html
更新時間:2026-05-24 18:25:22